Apache Kafka- Fundamentals
In the previous post, we learned what a messaging system is and the Role of Apache Kafka. In this post we will dive deep into Apache Kafka – We will learn Kafka cluster, brokers, topics, partitions, replicas, producers, consumers, consumer groups, Zookeeper, and how together make Kafka work.
![]()
Most of Kafka revolves around Kafka Cluster, Broker, and Topics, so let’s start our discussion with Kafka Cluster and Broker.
What’s a Kafka Cluster and Kafka Broker?
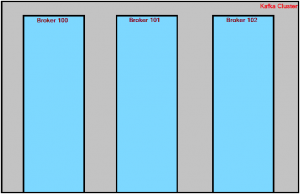
A Kafka cluster is composed of multiple brokers (machines). A broker is an actual server/machine on which data resides.
In other words, we can say that a Kafka Cluster uses multiple machines and each machine is called a Broker.
Example: Suppose there are 3 server machines – each machine is called a Broker, all 3 machines combined together are called Kafka Cluster. Each Broker in the Kafka cluster will be identified with a numeric id (100, 101,102 …).
More on brokers once we understand Kafka topics.
So what is a Topic? – It’s a particular stream of data or in words, it’s a holder of particular messages. It’s similar to a table in a database – a table has a name and the table holds only a particular type of data, there can be millions of rows in that table, but of the same type. e.g. an employee table – has some columns and the data stored / rows are related to an employee (like name, age, dept, role, etc.).
Similarly, in Kafka, every Topic has a name (more on naming conventions later), and a particular stream data /message is stored in a topic. e.g. stream of employee data.
In Kafka – each topic is split into partitions – Each topic can have 2 or more partitions, the best practice is to provide 3 partitions per topic. Each partition will have numbers that start with 0(zero) and can go to infinite numbers.
Note: while creating topics in Kafka, you need to provide the topic name, no. of partitions, and replication factor. – More on this later in the post.
Topics Hold stream od Data / Message, every message in each partition will get an incremental id – this id is called an offset. If 5 messages are sent to 0 partitions so the first message coming in will have offset 0, next will have 1, and so on. Similarly the with being offset id for partition 1 and partition 1 and 2